Using DBT Tests To Validate Data Quality For Machine Learning
13th Dec 2024
When training machine learning models, data quality is paramount. The common saying goes: garbage in, garbage out. That is to say, if you want high quality inference, you need to train on high quality training data.
For my ML use case, I am storing my data in a data warehouse in clickhouse. My machine learning model calculates the odds for greyhound races, and uses past data to classify the runners into the class of 1 (win) or 0 (lose). I am using an XGBoost classification model, and so I am able to get the probability of a win or loss, and by scaling it over the race field and taking
I can now gamble based on my model's predictions.
But, it is crucial that only high quality data is passed into the model, because if malformed or incorrect data is passed in, the model can get confused, which will hinder it's ability to learn the correct relationships between a runner's past performance and whether it will win or lose.
I need a roboust way to ensure my data is high quality, and my solution needs to easily integrate with my data stack which uses DBT and clickhouse. Luckily, DBT includes a testing framework, which I will leverage here to ensure the quality of the data I will train my model on.
DBT Tests
The official guide is here. Firstly, let's diagnose the issue.
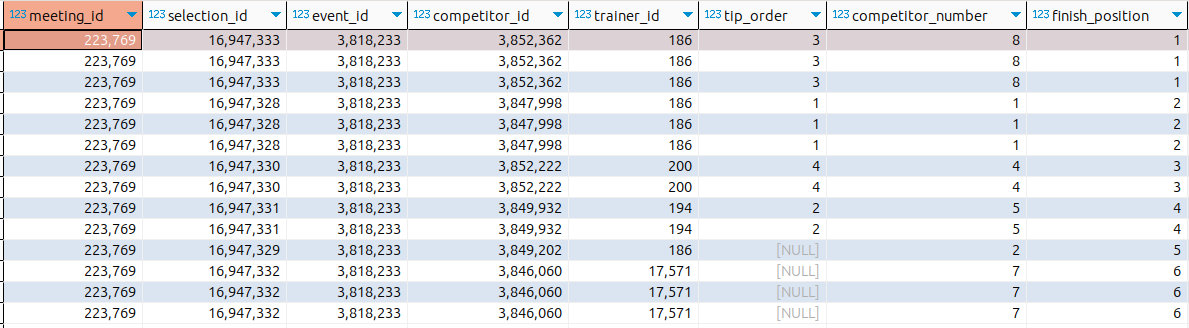
You will notice that some of those entries are duplicated, we need to stop this from happening. We also need to ensure it does not happen again...
Let's write a test:
I start by creating a file in the tests directory in my DBT project, and inside I create a new file test_results_unique.sql:
SELECT event_id, selection_id, COUNT(*)
FROM {{ ref('results') }}
GROUP BY event_id, selection_id
HAVING COUNT(*) > 1
The contents of the file is an SQL query which will be empty if the data passes the test. If the query has results, the test will fail.
I now run my test by writing into the command line:
dbt test --select test_results_unique
to which I get the expected:
09:24:47 Running with dbt=1.8.4
09:24:47 Registered adapter: clickhouse=1.8.1
09:24:47 Found 24 models, 1 test, 459 macros
09:24:47
09:24:48 Concurrency: 1 threads (target='dev')
09:24:48
09:24:48 1 of 1 START test test_results_unique .......................................... [RUN]
09:24:48 1 of 1 FAIL 155608 test_results_unique ......................................... [FAIL 155608 in 0.09s]
09:24:48
09:24:48 Finished running 1 test in 0 hours 0 minutes and 0.49 seconds (0.49s).
09:24:48
09:24:48 Completed with 1 error and 0 warnings:
09:24:48
09:24:48 Failure in test test_results_unique (tests/test_results_unique.sql)
09:24:48 Got 155608 results, configured to fail if != 0
09:24:48
09:24:48 compiled code at target/compiled/greyhounds_python_dbt/tests/test_results_unique.sql
09:24:48
09:24:48 Done. PASS=0 WARN=0 ERROR=1 SKIP=0 TOTAL=1
Great! By adding tests like this, I can ensure I am only training my ML model using high quality data, this will improve my results when it's time to infer.